 如何确保消息不重复消费
如何确保消息不重复消费
# 一、消息重复消费的情况
假设消息队列中有三条消息,现在消费者一次性拉取了三条消息,并且此刻正在消费第二条消息:
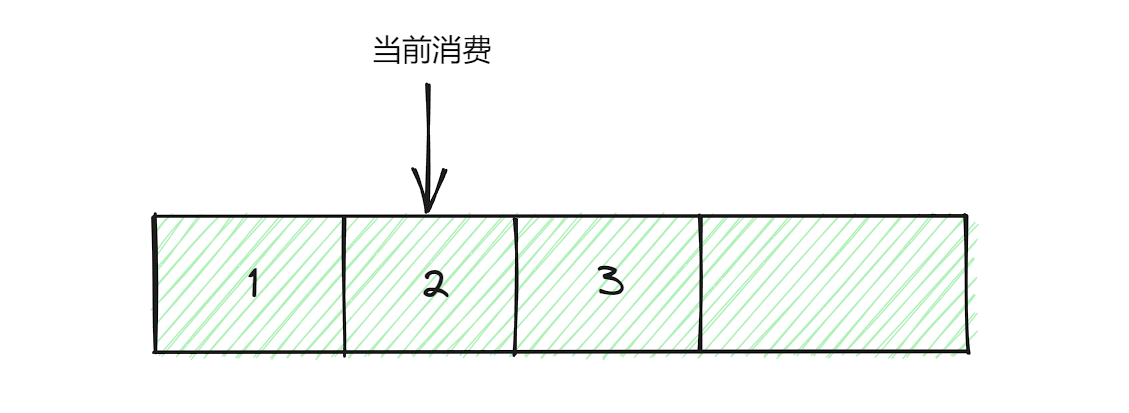
如果消费者是消费完毕之后再提交位移,也就是说现在位移仍然是1,在消费第二条消息的时候,消费者down了,等消费者恢复过后,是从第一条消息进行拉取,也就是第一条消息重复消费了。
# 二、幂等性概述
首先来阐述一下幂等性:幂等是一个数学与计算机学概念,在数学中某一元运算为幂等时,其作用在任一元素两次后会和其作用一次的结果相同。
在计算机中编程中,一个幂等操作的特点是其任意多次执行所产生的影响均与一次执行的影响相同,比如:
- 我们的查询请求,多次查询结果是一样的(保证数据库没变动情况下),那么这就是幂等。
- 我们的累加代码逻辑,多次执行结果是不一样的,那么这就是非幂等。
总结一下:对于幂等的方法,不用担心重复执行会对系统造成任何改变。
# 三、解决重复消费问题
# 1、利用数据库的唯一约束实现幂等
当我们消息传递过来的时候,我们可以根据消息的特性在数据库中设计一张流水表,并为这个流水表设置一个唯一索引。那么消息先插入DB,然后后续业务逻辑根据DB来进行执行。
基于这个思路,不光是可以使用关系型数据库,只要是支持类似“INSERT IF NOT EXIST”语义的存储类系统都可以用于实现幂等,比如,可以用 Redis 的 SETNX 命令来替代数据库中的唯一约束,来实现幂等消费。
# 2、为更新的数据设置前置条件
刚才我们说到累加这种操作不具有幂等性的,但是如果在累加之前,进行前置条件判断那么就具备幂等性了。
a每次累加10 修改为 a在等于100的时候才累加10
对应到消息队列中的使用时,可以在发消息时在消息体中带上当前的业务字段,在消费的时候进行判断数据库中,当前业务字段是否与消息中的业务字段相等,只有相等才执行变更操作。
# 3、记录并检查操作
有一种通用性最强,适用范围最广的实现幂等性方法:记录并检查操作,也称为“Token 机制或者 GUID(全局唯一 ID)机制”,实现的思路特别简单:在执行数据更新操作之前,先检查一下是否执行过这个更新操作。
具体的实现方法是,在发送消息时,给每条消息指定一个全局唯一的 ID,消费时,先根据这个 ID 检查这条消息是否有被消费过,如果没有消费过,才更新数据,然后将消费状态置为已消费。
# 四、幂等Producer
kafka生产者默认不是幂等的,指定 Producer 幂等性的方法很简单,仅需要设置一个参数即可:
props.put(“enable.idempotence”, ture)
// 或者
props.put(ProducerConfig.ENABLE_IDEMPOTENCE_CONFIG, true)
底层具体的原理很简单,就是经典的用空间去换时间的优化思路,即在 Broker 端多保存一些字段。当 Producer 发送了具有相同字段值的消息后,Broker 能够自动知晓这些消息已经重复了,于是可以在后台默默地把它们“丢弃”掉。
但是幂等Producer有一定局限性:
首先它只能保证单分区的幂等性,也就是说只能保证某一个主题的其中一个分区不出现不重复的消息,它无法实现多个分区的幂等性。
其次,它只能实现单会话上的幂等性,不能实现跨会话的幂等性。
针对这样的局限性,我们可以通过一定手段来实现全分区的消息不重复:
由于kafka分区器会根据key来发送到不同的分区,所以我们针对不同业务线设置不同的key,那么同一分区下就是相同业务线的消息,在利用幂等Proudcer来保证同分区的消息不重复。
# 五、事务性Producer
事务型 Producer 能够保证将消息原子性地写入到多个分区中。这批消息要么全部写入成功,要么全部失败。另外,事务型 Producer 也不惧进程的重启。Producer 重启回来后,Kafka 依然保证它们发送消息的精确一次处理。
设置事务性Producer方法如下:
- 和幂等性 Producer 一样,开启 enable.idempotence = true。
- 设置 Producer 端参数 transactional. id。最好为其设置一个有意义的名字。
producer.initTransactions();
try {
producer.beginTransaction();
producer.send(record1);
producer.send(record2);
producer.commitTransaction();
} catch (KafkaException e) {
producer.abortTransaction();
}
同时需要在消费端进行设置 isolation.level参数的值即可,当前这个参数有两个取值:
read_uncommitted:这是默认值,表明 Consumer 能够读取到 Kafka 写入的任何消息,不论事务型 Producer 提交事务还是终止事务,其写入的消息都可以读取。很显然,如果你用了事务型 Producer,那么对应的 Consumer 就不要使用这个值。read_committed:表明 Consumer 只会读取事务型 Producer 成功提交事务写入的消息。当然了,它也能看到非事务型 Producer 写入的所有消息。
事务性Producer更多是在流处理中,并且事务Producer会消耗更多的性能。